


华为GaussDB生态与标准CTO 王伟民
此次分享,将为大家介绍一下华为数据库业务的进展情况。从分享华为数据库的三大发展阶段、数据库面临的三个挑战,到华为如何聚焦两个差异化做出竞争力的构筑,再到最后介绍华为打造的以高斯定义为品牌的两款企业级数据库,总结下来就是“3322”。
首先,介绍一下华为数据库的发展历程。
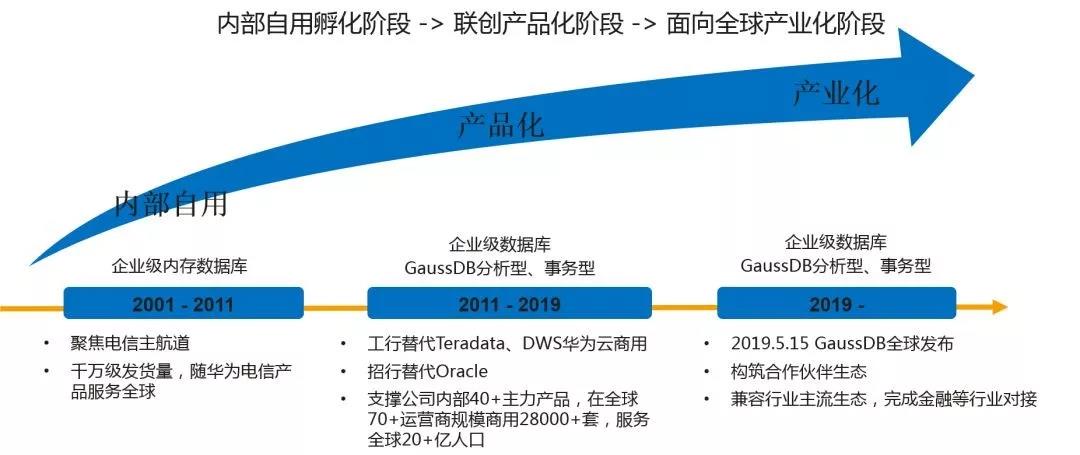
华为从2001年底开始进入数据库领域,到今天为止接近20年,中间走过了三个阶段:前面10年基本上为公司的主航道,也就是围绕公司的电信业务展开,研发了分布式内存数据库,主要为了在电信领域里面满足在线计费业务的需要。2011年底进入第二个阶段——联合创新阶段,我们公司成立了2012实验室。2012实验室是公司面对未来不确定场景,去为自己打造的诺亚方舟。我们从11年到去年年底为止,差不多8年时间,分别通过和工商银行、招商银行联合创新,分别推出了企业级的分布式OLAP数据库、分布式OLTP数据库产品。2019年5月15日,华为面向全球正式发布了以GaussDB为品牌的企业级分布式数据库,宣告华为数据库正式进入第三发展阶段——产业化阶段。该阶段内华为将携手产业合作伙伴共同打造开放繁荣的数据库产业生态。在金融领域,华为携手神州信息瞄准金融开放、安全领域首发一体化解决方案,覆盖芯片到服务器到操作系统数据库到应用,再到全栈自主研发的解决方案。
到目前为止这两款数据库都可以部署在公有云、私有云,在华为内部电信场景广泛使用;并且华为消费者云、华为公有云被用户广泛使用,到目前为止我们在全球服务60多个国家,有超过1500个客户。
第二,为什么华为要进入到这个领域。
从上个世纪70年代到今天,数据库走过了50年的历程。今天我们为什么要做企业级的数据库研发?原因有三:
第一,现在是数字化智能化的时代,是万物感知万物互联,海量的用户和交易;使得目前我们的业务系统规模非常庞大在线下超过几百个节点的系统已不再罕见,在线上预估很快会出现上万节点的集群规模,如此复杂的集群规模其实是非常难以去运营和管理的。第二,这些半结构化、结构化数据如何统一进行计算和管理,如何进行优化,也是一个很大的挑战。第三,在最初的数据库领域,它其实是面向数据中心里面有限的资源进行设计和优化的,现在摩尔定律其实面临一个瓶颈,在众多领域有着多样化的计算平台出现,如何通过软件实现计算能力的整体协调和优化?
经过对这三个方面的思考,我们选择进入企业级数据库领域,聚焦两个方面进行差异化竞争力构筑:
第一方面是聚焦鲲鹏生态,为充分发挥多核的优势,推出了超并行技术,将数据库的性能提高到新的高度。所谓超并行我们指的是四层的并行,首先可以实现节点间的并行、节点内多线程、单指令多数据SIMD,动态代码生成以及动态编译组合在一起组成了超并行处理,整体上性能差不多有50%的提升。
第二方面是多样化的算力。传统的X86非常擅长标量数据的处理,GPU擅长处理向量数据、NPU等AI芯片擅长处理张量数据、还有面向特定领域可编程的FPGA。我们在千亿级的图像比对场景里面进行高维特征向量比对,能够实现千亿级数据秒级响应,与原来的处理平台相比大概是8倍的提升,华为正是以此来打造差异化竞争力。
接下来是GaussDB分布式数据库,一款是事务型数据库OLTP Database,一款是分析型数据库OLAP Database。
第一款就是分布式OLTP数据库。

很多银行持续追求三个9甚至五个9,通用数据库通常在保障数据不丢失的情况下,其实是在追求不断降低非计划宕机时间,提升RTO,业界的一个标杆大概做到30秒左右。通过引入Switch Turbo技术,结合全局缓存、高速网络及网络协议创新,GaussDB 在AZ内能做到秒级的RTO。在招商银行的实践中,GaussDB管理的数据容量提升10倍,AZ内故障恢复速度提升30倍。
第二款就是分布式OLAP数据库:
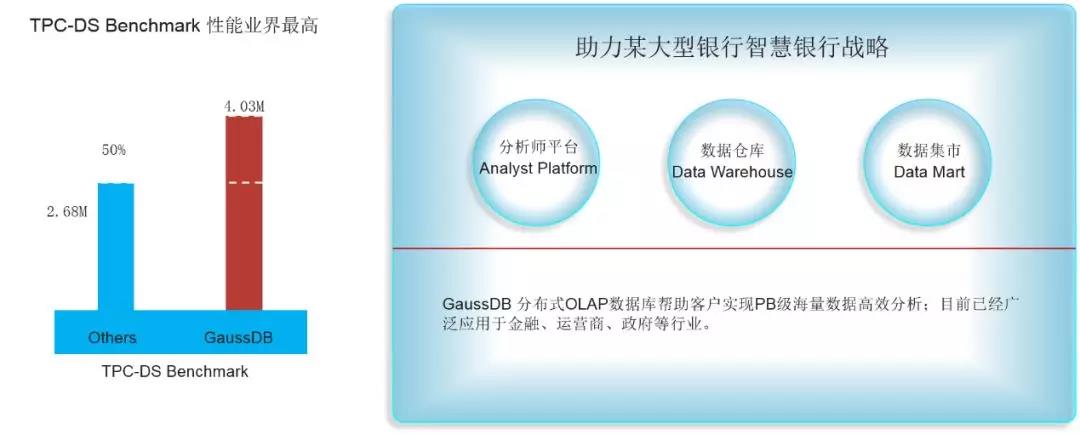
大家都知道,金融领域数仓的传统模式是T+1模式,即夜间进行数据的准备(转换、加载等),白天进行数据的分析和展现。现在很多业务场景里面,包括风控,客户希望它从事后走向事中,甚至走向预防。因为我们引入了前面所讲的超并行技术,使得我们能够支撑客户的业务创新,实现近实时的分析负载。
GaussDB既支持在客户的数据中心部署,也支持在客户的私有云,公有云部署。数据库的部署形态,到目前为止支持极致高性能的主备模式,极致高可用的集群部署,还有支持金融两地三中心、三地五副本的容灾部署,还有全分布式的部署等四种形态。因为华为也提供硬件基础设施,如果客户追求极致的性价比,将来还可能有一体机的形态出现。
非常感谢大家的聆听,3322,三个阶段,三大挑战,聚焦两个差异化的竞争力构筑,还有两款企业级的数据库,再次感谢大家。
